Patent Filed: Adaptive Prompt Orchestration with Signal-Driven Feature Switching
ROIRoute has filed U.S. Provisional Patent Application No. 64/013,836 covering six integrated innovations — from signal saturation detection to Thompson Sampling for multi-provider LLM selection — built by one architect using AI.
What We Filed — And Why We're Disclosing It Now
On March 23, 2026, the United States Patent and Trademark Office accepted a provisional patent application — number 64/013,836 — titled "Adaptive Prompt Orchestration System with Signal-Driven Feature Switching for Real-Time AI Conversations, Incorporating Thompson Sampling for Multi-Provider LLM Selection, Config-Driven Multi-Tenant Pipeline Orchestration, Server-Side Conversation Attribution Bridge, and Machine Learning-Optimized Conversation Trigger Thresholds." That is not a title designed for marketing. It is designed for the examiner who will read it and for the prior art search that will test it. Every word in that title maps to a specific technical claim. Ten claims total. Each one describing a mechanism that, to our knowledge, does not exist in any prior system, patent, or published architecture.
A provisional patent establishes a priority date. It means that as of this morning, the inventions described in this filing are on record. Anything published after today that resembles these mechanisms will be measured against our specification. The filing date is a line in the sand. Everything we describe below is now protected by the filing date — not because we want to teach competitors how to build it, but because the filing protects the architecture while disclosure establishes the timestamp. That is how the patent system works. You file, then you disclose. We have filed. Now we disclose.
What follows is a technical explanation of six innovations that are now running in production, serving real conversations, qualifying real leads, and generating real revenue. This is not a research paper. This is not a roadmap. This is architecture that exists, deployed on AWS, processing live traffic today. Every mechanism described below has been reduced to practice. The patent specification includes the evidence.
The Architecture at a Glance
Before we go deep on each innovation, here is the system as a whole. Every component you see below is live, deployed, and serving production traffic. The Routing Orchestrator and Context Pipeline are AWS Step Functions. The configuration tables are DynamoDB. The cache layer is ElastiCache Redis. The event bus is EventBridge. The LLM providers are real API integrations — seven of them — with Thompson Sampling selecting between them on every conversation exchange.
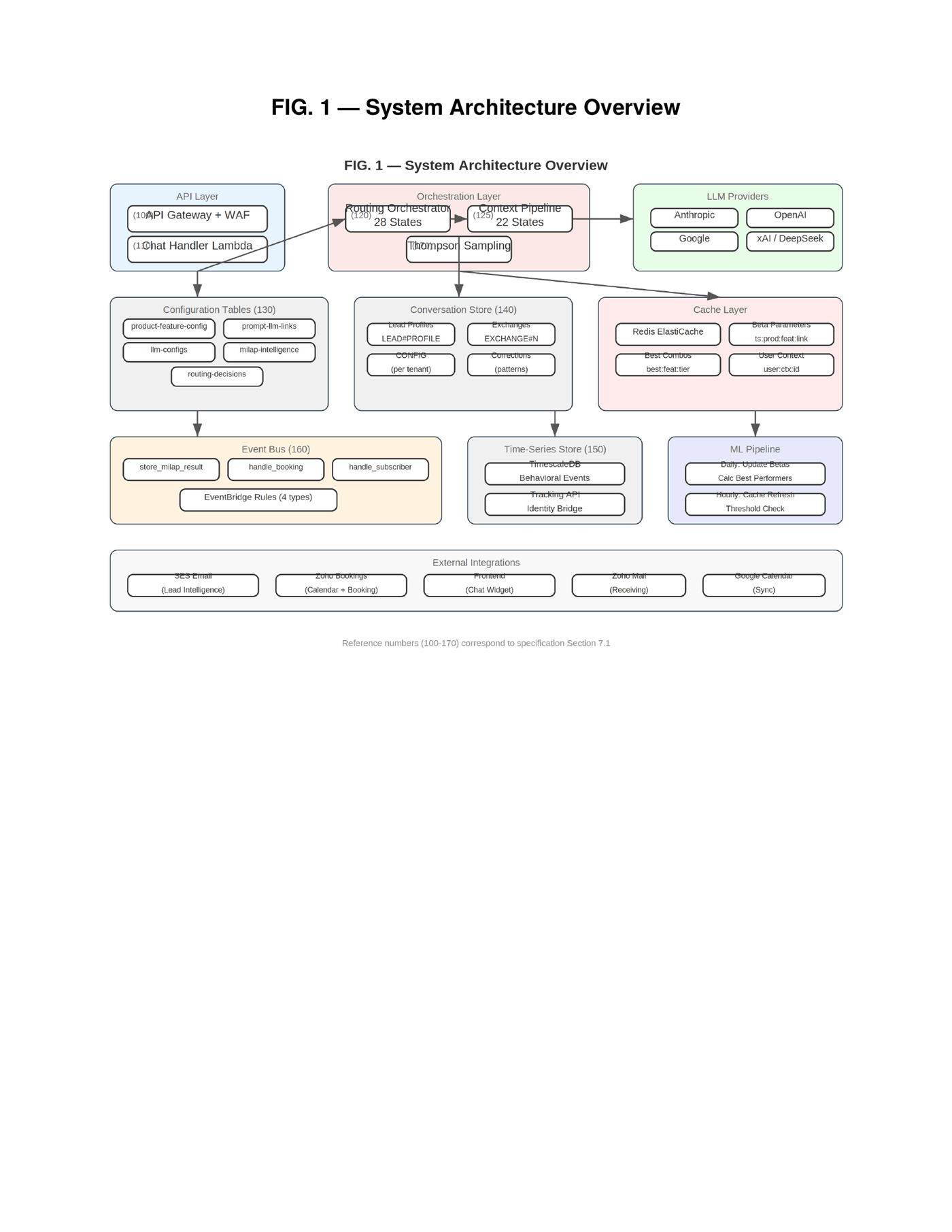
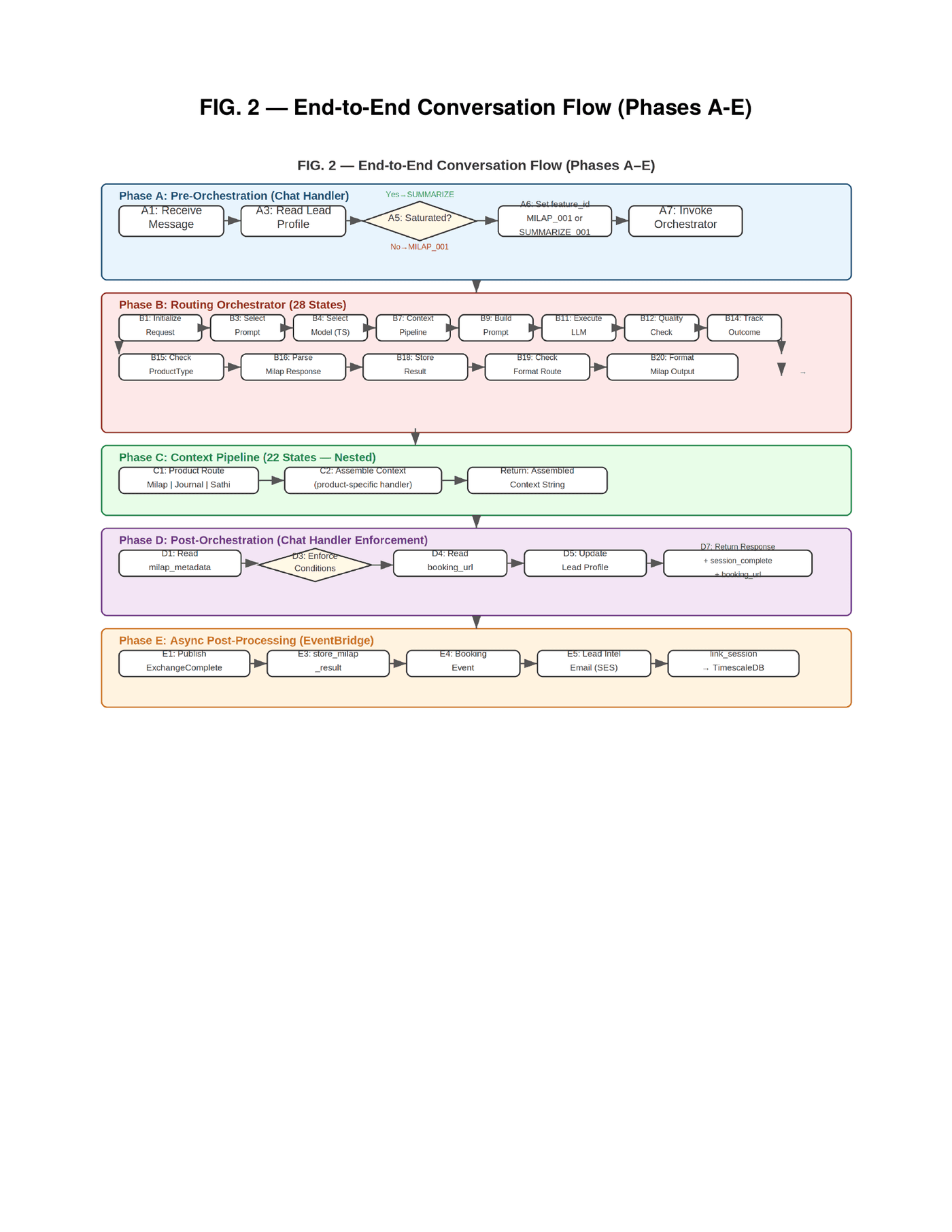
The complete data flow for a single conversation exchange traverses five phases — from the visitor's message arriving at the API Gateway through pre-orchestration signal analysis, through the 28-state Routing Orchestrator, through the nested 22-state Context Pipeline, through post-orchestration enforcement, and finally into asynchronous post-processing via EventBridge. Five phases. Fifty states. One conversation turn.
The Problem That Required Inventing Something New
Every AI conversation system on the market has the same structural flaw. They ask the language model to do two things simultaneously: conduct the conversation and decide when the conversation has achieved its objective. This is like asking a salesperson to both close the deal and audit their own pipeline metrics in real time. The salesperson is optimized for rapport, for reading the room, for keeping the conversation alive. The auditor is optimized for recognizing when enough data has been collected. These are different cognitive operations. Asking one system to perform both produces a system that is mediocre at each.
In practice, what we observed in production environments was that language models would continue asking qualification questions for fifteen or more exchanges when sufficient signals had been captured by exchange five or six. The model could not assess its own progress. It could not recognize that the remaining undetected signals were not missing — they were inapplicable. A landscaper will never trigger the "multiple tools" signal that an agency owner would. The model did not understand this. It kept probing. The visitor grew tired. The conversation abandoned. The lead was lost. Not because the AI was bad at conversation — it was excellent at conversation. It was bad at knowing when to stop.
This is not a prompt engineering problem. You cannot instruct a language model to reliably assess its own conversation saturation point, because saturation is not a property of the conversation text. It is a property of the accumulated signals relative to the visitor segment relative to the business context — a computation that requires structured data the model does not have access to in its context window and should not be trusted to evaluate even if it did. The solution is not a better prompt. The solution is to take the decision away from the model entirely and give it to the server.
The LLM does not decide when to switch. The LLM does not know a switch has occurred. The server reads the signals, evaluates the thresholds, and changes the prompt configuration before the next orchestrator invocation. Same pipeline, different data. The model is a tool. The server is the operator.
Innovation 1: Signal Saturation Detection and Server-Controlled Feature Switching
The core invention is a mechanism we call signal saturation detection. During each exchange in a conversation, the language model produces structured metadata alongside its visible response — qualification signals, each with a value and confidence score. These signals are accumulated in a persistent store. Before each orchestrator invocation, the server reads the accumulated state and evaluates three conditions: Has the exchange count reached a minimum threshold? Has the qualification score — a weighted sum of detected signals — exceeded a score threshold? Is the conversation still in its qualifying phase?
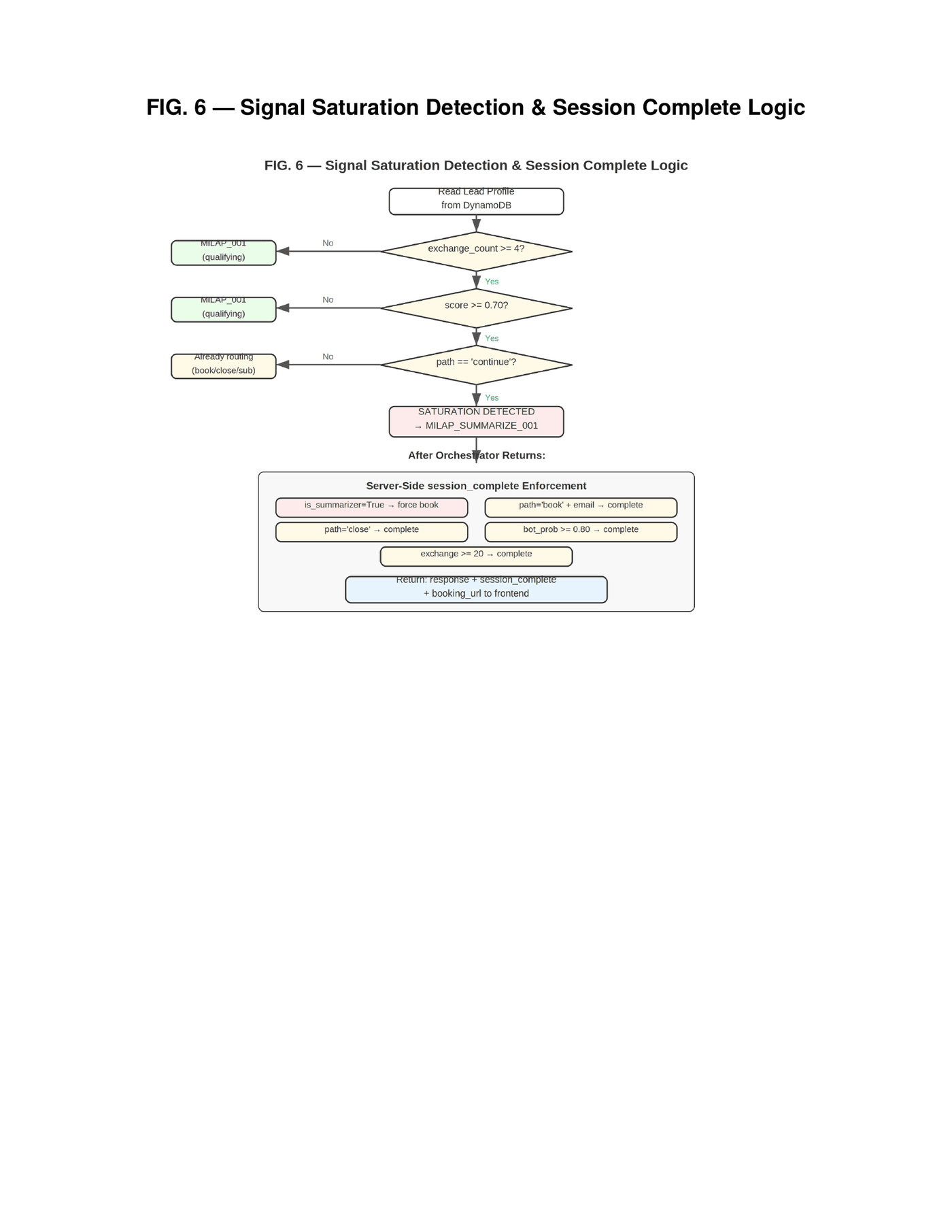
When all three conditions are met, the server performs the switch. It does not instruct the model to change behavior. It does not inject a system message saying "now summarize." It changes the feature identifier in the orchestrator payload — for example, from a qualifying feature identifier to a summarizing feature identifier — and invokes the exact same pipeline. The prompt selection module inside the orchestrator loads whichever prompt configuration corresponds to the feature identifier it receives. The qualifying feature returns the qualifying prompt — open-ended, signal-extracting, conversational. The summarizing feature returns the summarizer prompt — structured, closing-oriented, booking-focused. Same Lambda function. Different database row. The feature identifiers are configurable per product and per tenant — any conversation product can define its own feature set with its own switching logic. The switch is invisible to the model and deterministic at the server.
But the switch alone is not sufficient. After the orchestrator returns the summarizer's response, the server applies a second layer of enforcement. If the summarizer flag is set, the server forces the booking action and session completion regardless of what the model output. If the visitor's email has been captured and the path is "book," session completion is forced. If bot probability exceeds eighty percent, the session is terminated to prevent resource waste. If the exchange count hits twenty, an absolute ceiling is enforced. Each condition operates independently. Any single condition triggers enforcement. This is not one backstop. It is five, layered, operating simultaneously. The model cannot override any of them.
The innovation here is recognizing that not all qualification signals are applicable to every visitor type. Prior systems treated missing signals as incomplete data. Our system treats high signal density combined with a plateaued score as saturation — the remaining signals are not missing, they are structurally irrelevant for this visitor. This reframing — from "incomplete" to "saturated" — is what enables the server to switch early and avoid the visitor fatigue that kills conversion rates.
Innovation 2: Thompson Sampling for Multi-Provider LLM Selection
Most production AI conversation systems still select their language model statically. You configure GPT-4 or Claude or Gemini and that is what runs for every conversation, every visitor, every segment. If the provider has an outage, your system has an outage. If a different model would produce better conversion rates for a particular visitor segment, you have no mechanism to discover this. If pricing changes make one provider suddenly twice as expensive, you absorb the cost or manually reconfigure. This is fragile, static, and blind.
Thompson Sampling as a technique for LLM routing is not new — academic research has explored multi-armed bandit approaches to model selection, and a handful of open-source routing projects have applied Beta distribution sampling to balance exploration and exploitation across providers. What those systems optimize for — response quality scores, latency, cost efficiency — is fundamentally different from what our system optimizes for. Our reward signal is not "did the response score well on coherence?" It is "did this visitor book a meeting?" The outcome that updates our Beta parameters is a real business event, not a proxy metric. That distinction changes what the system learns.
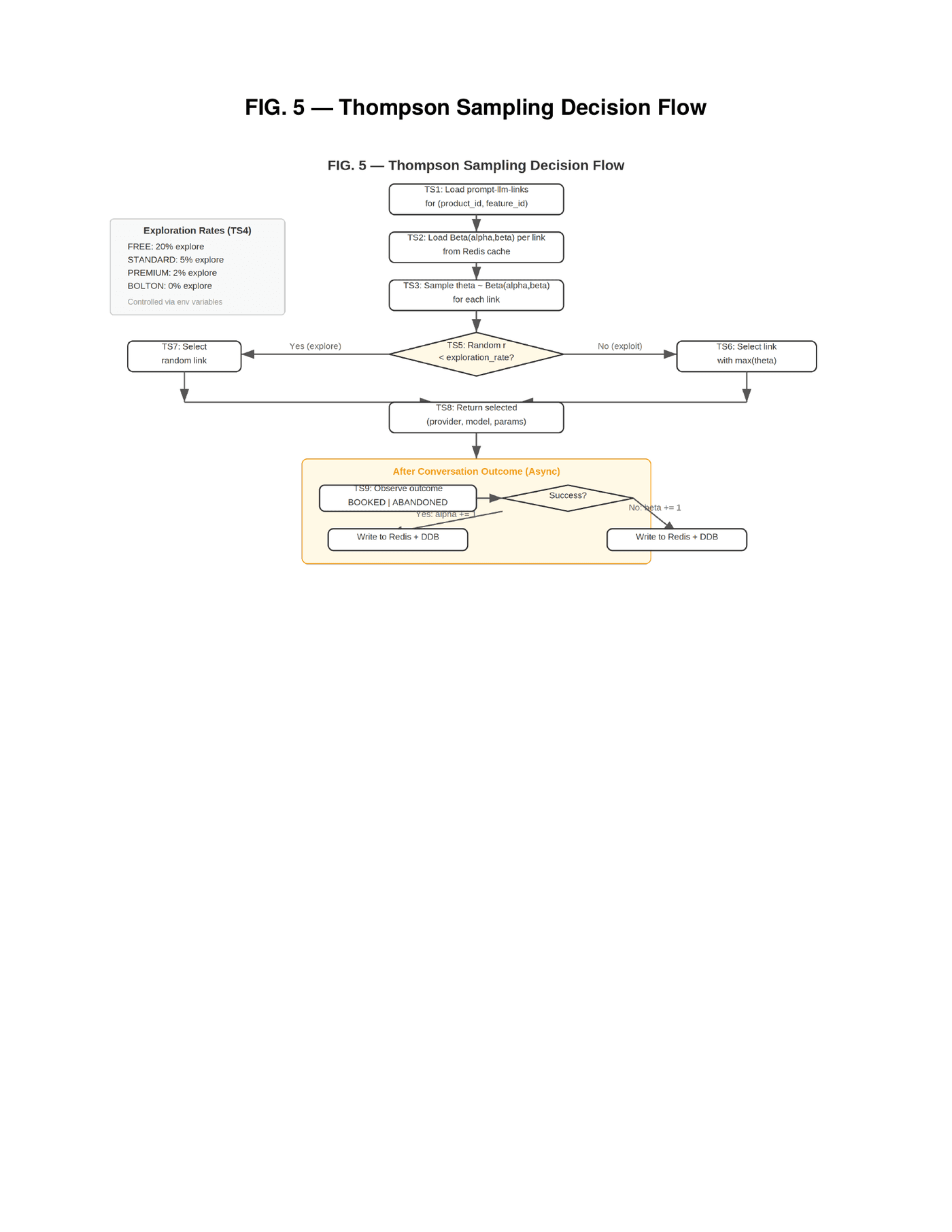
Our system treats model selection as a multi-armed bandit problem where each unique combination of product, feature, provider, model, and prompt variant constitutes an arm. For each arm, the system maintains a Beta distribution parameterized by alpha and beta — alpha incremented on successful business outcomes (booked meetings, subscriptions), beta incremented on failures (abandoned conversations, closed sessions without conversion). At runtime, the system samples from each arm's Beta distribution, generating a random score drawn from Beta(α, β) for each available option. With probability (1 minus the exploration rate), it selects the arm with the highest sampled score. With probability equal to the exploration rate, it selects a random arm.
The second innovation within this mechanism is that exploration rates are controlled by subscription tier — and this is a deliberate business architecture, not just an algorithmic parameter. Free-tier users explore at twenty percent — one in five conversations tries a random combination, generating learning data for the system. Standard-tier users explore at five percent. Premium-tier users at two percent. Bolton (add-on) users at zero — they always get the best known combination. Paying customers receive optimized experiences while free-tier users contribute disproportionately to system learning. The free tier is not a loss leader. It is an optimization engine. No existing LLM routing system ties exploration rates to subscription tiers as a structural business mechanic. The bandit algorithm is known. The application of tiered exploration as a SaaS business model within a conversation-to-revenue pipeline is not.
The parameters are cached in Redis for sub-millisecond access during live conversations and persisted to DynamoDB for durability. After each conversation outcome — asynchronously, via EventBridge — the parameters are updated. The system converges toward the best-performing combination for each product-feature-segment intersection automatically, without human intervention, continuously, in production. Seven providers are currently integrated: OpenAI, Anthropic, Google, xAI, DeepSeek, Mistral, and Groq. Adding a new provider requires a database entry and an API adapter. No pipeline changes.
Multi-provider fallback was not optional. It was designed in from day one as resilience infrastructure — against geopolitical risk, grid instability, and supply chain fragility. If Anthropic has an outage, the system routes to OpenAI. If OpenAI is slow, it routes to Gemini. The conversation continues. The visitor never knows.
Innovation 3: The ROI Engine — Config-Driven Pipeline Orchestration
The pipeline that executes every conversation — every product, every tenant, every feature — is a single shared architecture. The Routing Orchestrator is an AWS Step Function comprising twenty-eight discrete states. It handles request initialization, user context loading, access control, Thompson Sampling selection, prompt configuration retrieval, context assembly, prompt building, LLM execution with three-tier fallback, response quality validation with repair and fallback paths, product-specific post-processing, outcome tracking, and result storage. Every conversation, regardless of product or tenant, traverses this same state machine.

Nested inside the Routing Orchestrator is the Context Pipeline — a second Step Function with twenty-two states. It routes to product-specific context assembly based on a configurable product identifier. A lead qualification product gets context assembled from business configurations, accumulated signals, and learned patterns. A journaling product gets contextual data with emotion tracking. An education product gets student progress and knowledge retrieval via semantic search. Each route returns the same output format — an assembled context string — so the Routing Orchestrator and LLM execution remain completely product-agnostic. The LLM never knows which product it is serving. It receives a prompt and produces a response. Everything else is the pipeline's job.
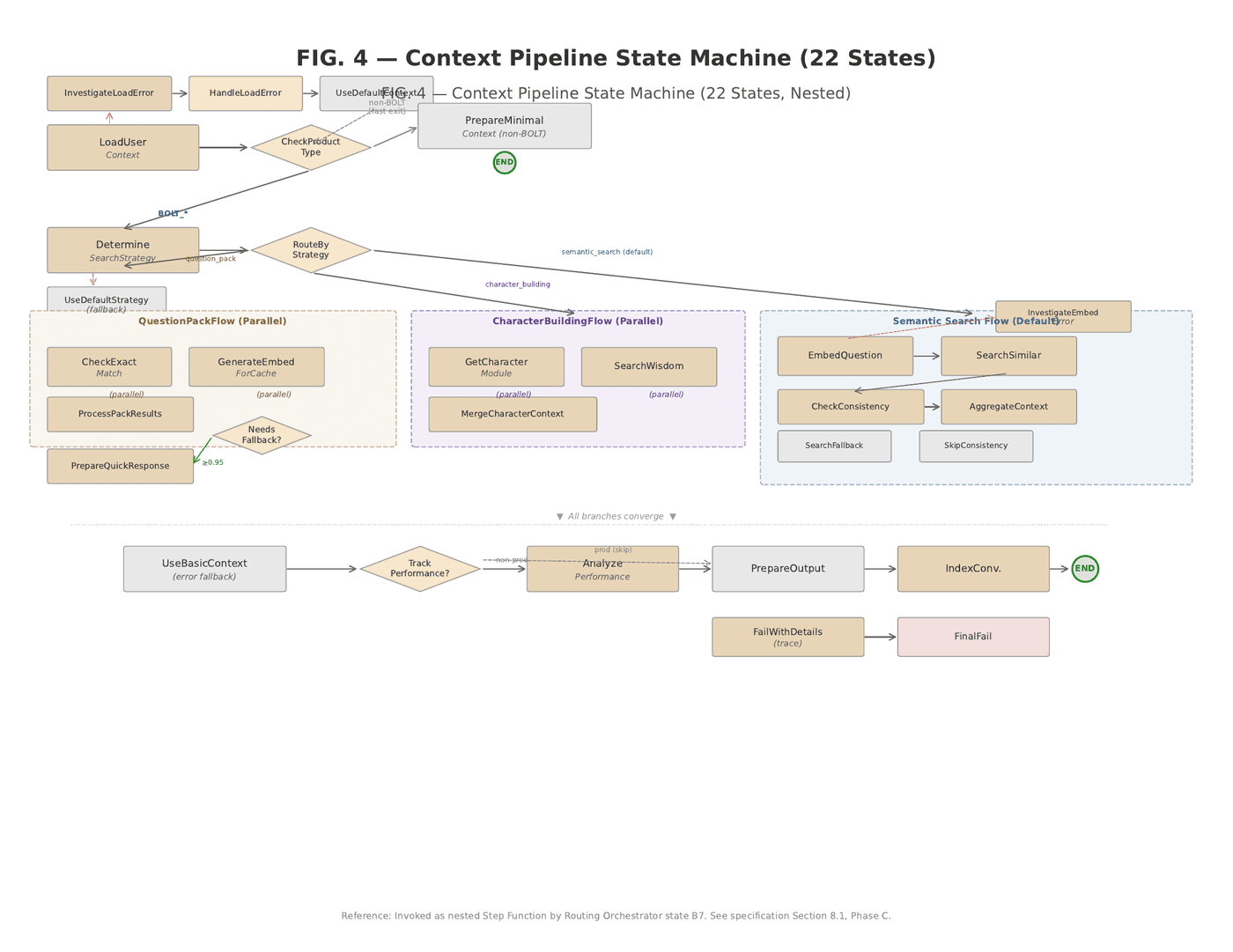
All behavior is controlled by five configuration tables in the database. A product-feature table stores prompt content per product, feature, tier, and variant. A prompt-model-links table maps features to available model combinations for Thompson Sampling. A model-configs table stores provider credentials and API parameters. A tenant-intelligence table stores tenant configurations, lead profiles, and exchange records. A routing-decisions table stores per-exchange outcome data for the optimization loop.
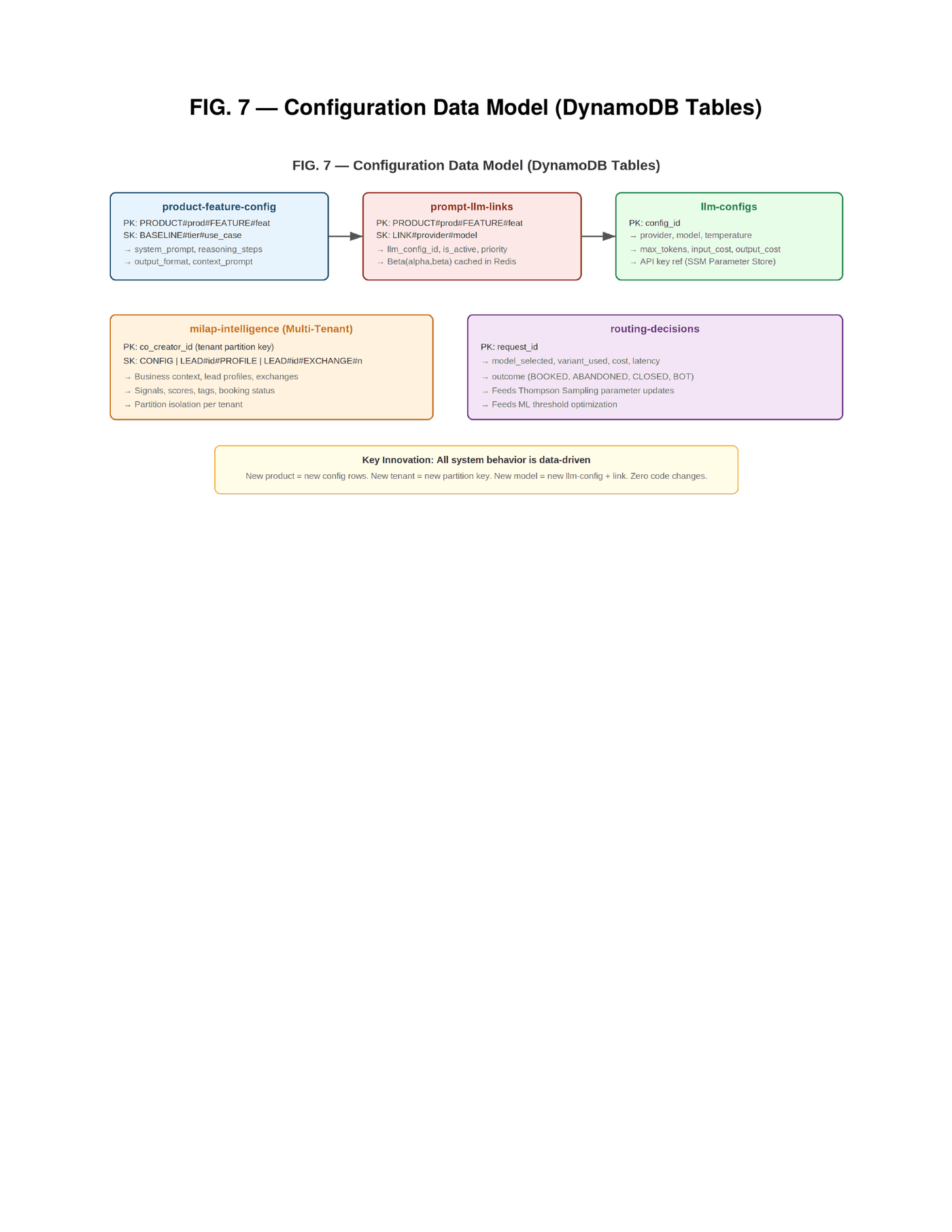
Adding a new product requires a config row, a prompt-model link, and a context route. Adding a new tenant requires a single configuration entry. Changing LLM providers requires updating link entries. No Lambda code changes. No deployments. No pull requests. This is a deliberate architectural counter-position to the agentic AI pattern currently dominating the industry conversation. Agentic systems give the LLM autonomy to decide what tools to call, what data to retrieve, and how to sequence operations. This sounds elegant. In production, it means dramatically higher token consumption, unpredictable execution paths, and projected failure rates that make the approach unsuitable for revenue-generating conversations where every abandoned session is a lost customer. Our approach is the opposite: the configuration defines exactly what each feature needs, parallel fetches retrieve data via primary keys, and the LLM receives a complete, pre-assembled context package. Context quality over autonomy.
Innovation 4: Server-Side Attribution Bridge
The advertising-to-outcome attribution problem has been slowly deteriorating for years. Cookie restrictions, ad-blockers, cross-domain tracking limitations, iOS privacy changes — each one removes a piece of the chain that connects "this person clicked an ad" to "this person booked a meeting." Browser-based analytics solutions lose between thirty and sixty percent of attribution data depending on the audience. For privacy-conscious audiences — which increasingly means everyone — the number is worse.
Server-side attribution itself is a growing category. Platforms like Cometly, Northbeam, and Triple Whale implement server-side tracking with deterministic matching via hashed emails and first-party identifiers. What they track is advertising performance — ad click to website conversion to purchase. What they do not track is what happened inside an AI conversation. They cannot tell you which qualification signals the AI extracted, what score the visitor reached, which model produced the best conversion outcome, or how the conversation's signal trajectory correlated with the business result. They close the attribution loop at the conversion event. Our system closes it at the conversation level — because in our system, the conversation is the conversion mechanism.
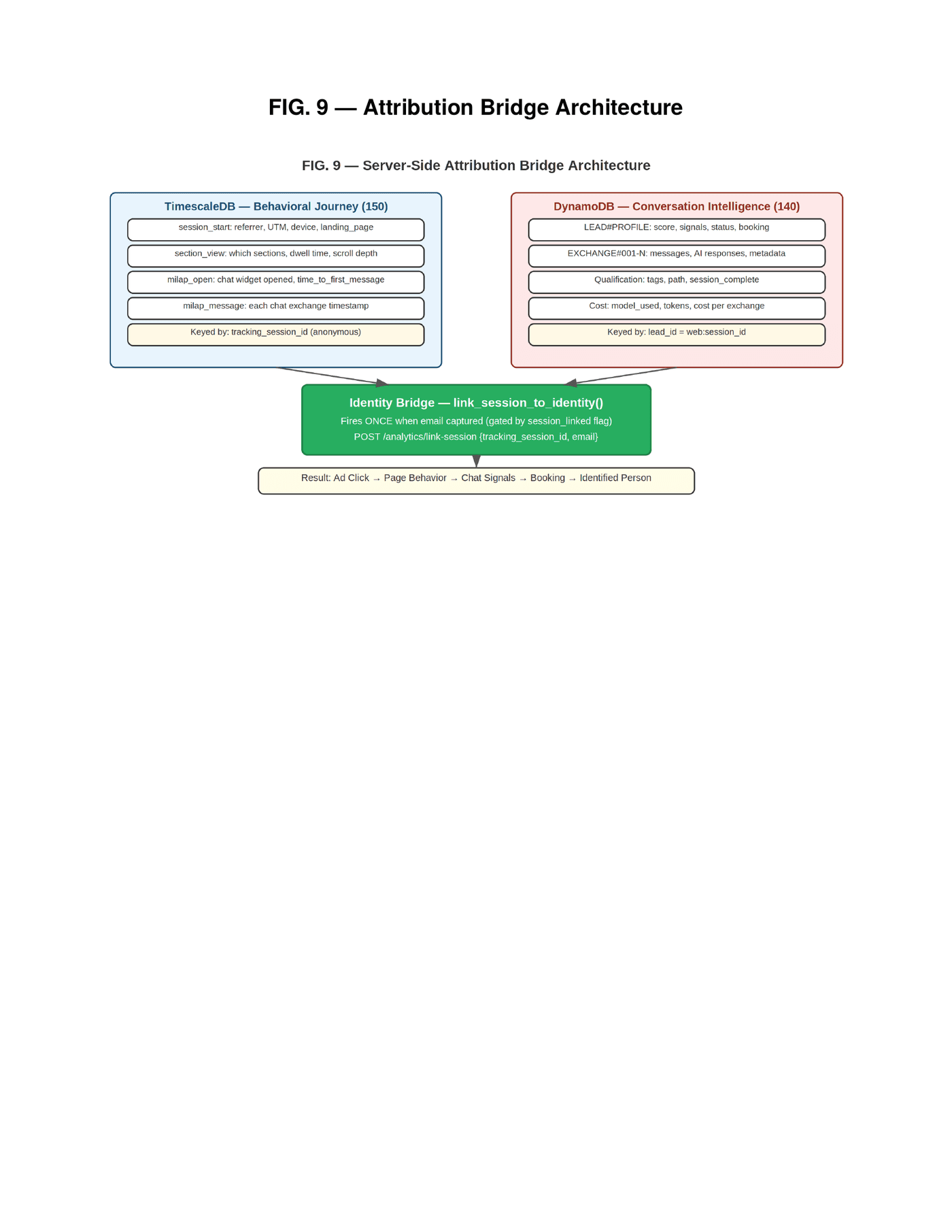
Our system implements a dual-database attribution architecture that operates entirely server-side. TimescaleDB stores behavioral journey events — session start with referrer URL and UTM parameters, section views with dwell times, scroll depth, FAQ interactions, chat widget opens, and individual chat exchange timestamps. All events are keyed by a server-generated tracking session identifier that is independent of browser cookies. DynamoDB stores conversation intelligence — qualification signals, scores, conversation turns, LLM costs, model selections, and booking outcomes.
These two databases are connected by a mechanism we call the identity bridge. During the conversation, when the visitor provides their email address, a post-processing Lambda — triggered asynchronously via EventBridge — checks whether the session has already been linked. If the email exists and the session has not been linked, it fires a one-time API call to the time-series database that associates the anonymous tracking session with the identified email. A session_linked flag on the lead profile ensures this fires exactly once per lead. After the link, the complete chain is reconstructable: which advertisement brought this person, which page sections they read, how long they engaged, when they opened the chat, what signals the AI extracted, what score they reached, whether they booked, and who they are. All server-side. All surviving ad-blockers. All operating without browser cookies.
Ad click to page behavior to conversation signals to business outcome to identified person. Complete attribution. Server-side. No cookies required. No browser tracking that can be blocked. The chain is closed by the conversation itself.
Innovation 5: ML-Optimized Conversation Trigger Thresholds
The signal saturation detection described in Innovation 1 uses configurable thresholds — minimum exchange count, score threshold, path condition. The initial values are human-configured defaults: switch at exchange four, when the score exceeds 0.70, while the path is still "continue." These defaults work. But they are not optimal, and they are not optimal differently for different visitor segments.
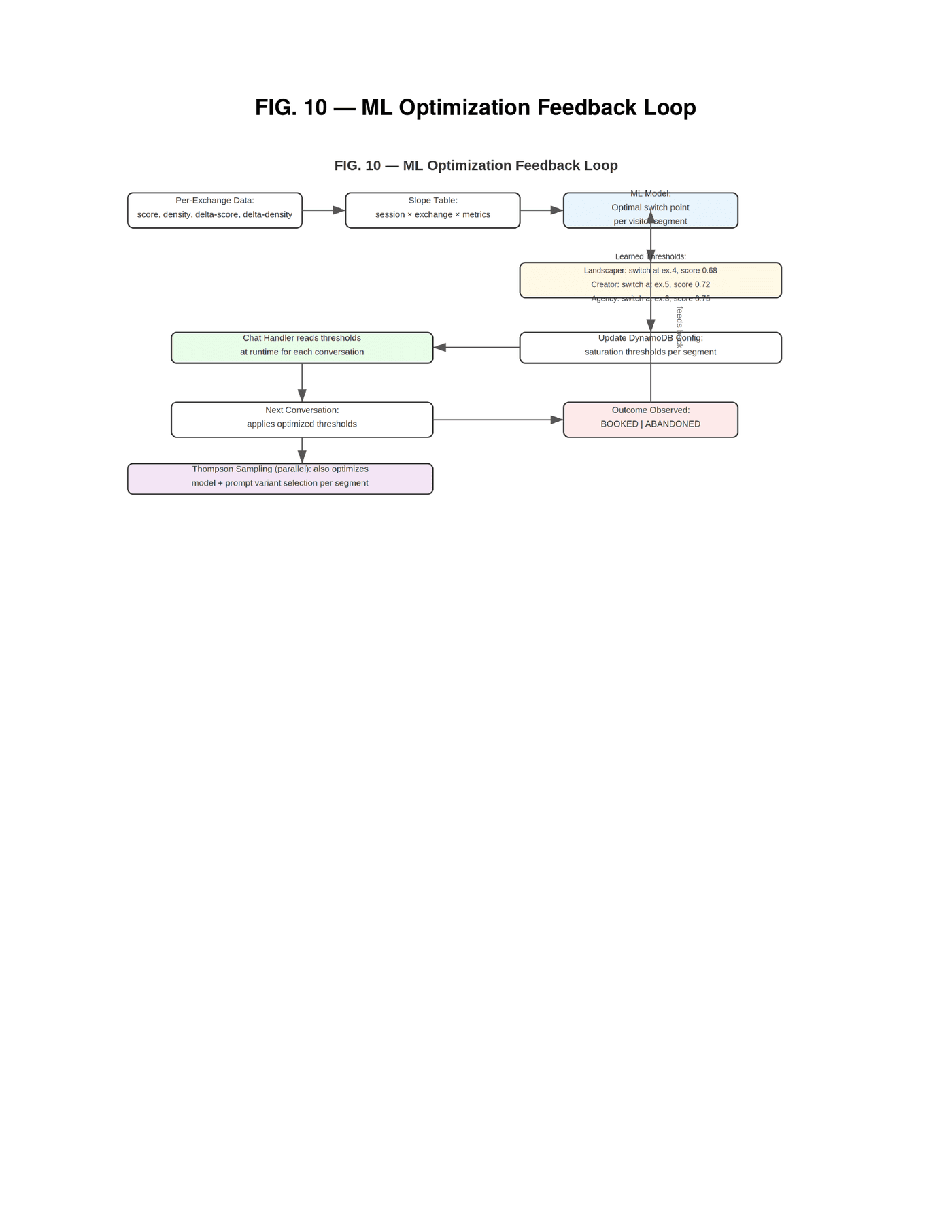
A landscaping business owner reaches saturation faster than an agency owner. The landscaper has fewer applicable signals and reaches the plateau earlier. The agency owner has more complexity in their business model and benefits from deeper probing. Switching both at exchange four with a 0.70 threshold is leaving conversion on the table for the agency owner and potentially switching too late for the landscaper. The optimal thresholds are segment-specific.
The system is architected to collect the data required for this optimization, and the collection infrastructure is live in production today. For every conversation, the routing-decisions and tenant-intelligence tables together store per-exchange qualification score, signal density, score delta between exchanges, exchange count at switch, feature used, model selected, cost, latency, and final outcome. This produces a slope table — score and density at each exchange — from which an ML model can learn the optimal switch point per visitor segment. The optimization objective is explicit: maximize booking rate while minimizing exchange count times cost per exchange. Find the point where additional conversation depth stops improving outcomes and starts wasting money.
The learned thresholds are written back to the configuration tables and read by the chat handler at runtime. The data collection pipeline is operational; the ML model that consumes this data to compute per-segment optimal thresholds is in active development. Early production conversations have already demonstrated the pattern the model will exploit — observed saturation at 0.79 for a landscaping visitor versus 0.95 for a course creator, with the landscaper reaching plateau two exchanges earlier. The data confirms that segment-specific thresholds will materially improve conversion efficiency. Thompson Sampling will explore threshold variations in parallel once the optimization model is deployed, bringing the entire conversation lifecycle — from first message through feature switch through booking — under continuous optimization pressure, learning from every outcome, adapting per segment, without human intervention.
Innovation 6: Asynchronous Event-Driven Post-Processing
The synchronous conversation flow — visitor sends message, server processes, response returns — is only half the system. After each exchange, the chat handler publishes an event to Amazon EventBridge. Four event types route through the bus, each consumed by dedicated Lambda functions operating asynchronously and independently of the conversation flow.
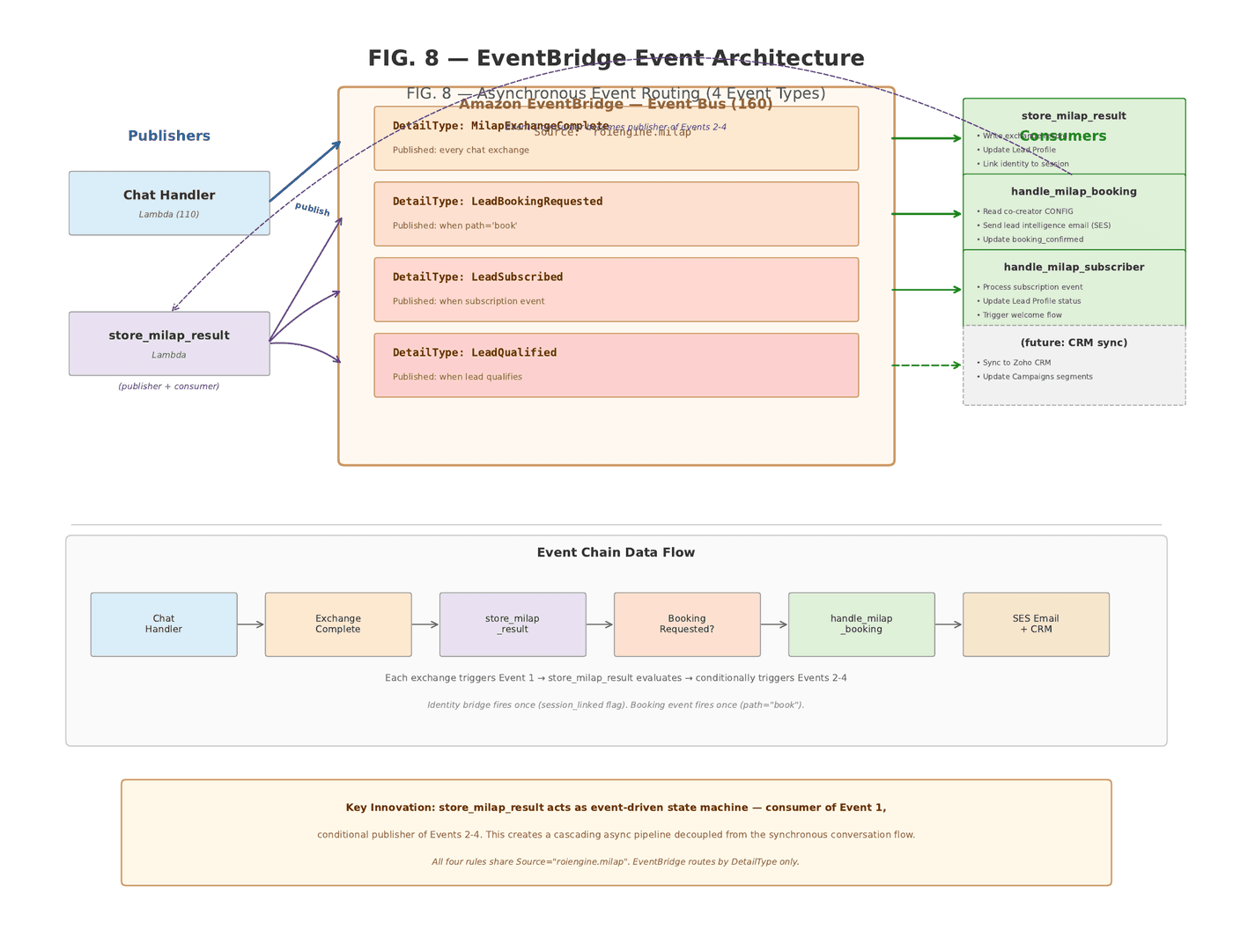
The first event — an exchange-complete event — fires after every exchange. Its consumer Lambda writes the rich exchange record, updates the lead profile with accumulated signals and scores, writes cost metrics to the routing-decisions table, and fires the identity bridge if applicable. This Lambda is not just a consumer. It evaluates the conversation state and conditionally publishes downstream events. If the path is "book," it publishes a booking-requested event. If a subscription event occurs, it publishes a lead-subscribed event. If qualification criteria are met, it publishes a lead-qualified event.
The second event, booking-requested, triggers a booking handler Lambda — which reads the co-creator's configuration, generates a lead intelligence email containing the qualification score, extracted signals, and suggested agenda topics, sends it via email service to the business owner before the meeting happens, and updates the lead profile with booking confirmation. The business owner walks into every meeting already knowing what the AI learned about the lead. The third event handles subscription flows. The fourth is reserved for CRM synchronization — integrating with CRM platforms to sync leads, update campaign segments, and close the loop between conversation outcomes and marketing analytics.
The architectural significance of this pattern is that the visitor's experience — the conversation response time — is completely decoupled from the post-processing complexity. The visitor gets their response in the time it takes to run the orchestrator. Everything else — storage, analytics, attribution, email, CRM — happens after. The system can add unlimited post-processing consumers without adding a single millisecond to response latency.
Why LangChain, LLM Routers, and Agentic Frameworks Don't Solve This
The AI orchestration landscape in 2026 has three dominant categories, each solving a piece of the problem while missing the whole. Understanding where they stop is understanding why the ROI Engine needed to be invented.
The first category is orchestration frameworks — LangChain, LangGraph, LlamaIndex. LangGraph is the most sophisticated of these: a graph-based orchestration runtime that lets you define agents as nodes, connect them with conditional edges, manage state across turns, and build multi-agent workflows with human-in-the-loop checkpoints. It is a powerful toolkit. It is also fundamentally a developer framework — it gives you the primitives to build an orchestration system. It does not give you the orchestration system itself. You still decide which model to call. You still configure the prompts. You still define the routing logic. You still build the optimization loop. LangGraph is a graph execution engine. The ROI Engine is a complete pipeline that includes model selection, prompt optimization, context assembly, quality validation, fallback chains, outcome tracking, and continuous learning — fifty states across two nested state machines, all driven by configuration, all shared across products and tenants. LangGraph gives you the hammer. The ROI Engine is the building.
More importantly, the agentic paradigm that LangChain and LangGraph are built around gives the LLM decision-making authority. The agent decides which tools to call, what data to retrieve, how to sequence operations. In research settings and internal tooling, this flexibility is valuable. In revenue-generating conversations — where every abandoned session is a lost customer and every unnecessary token is wasted margin — agent autonomy is a liability. Agents consume dramatically more tokens because they reason about what to do before doing it. Their execution paths are unpredictable, making debugging and optimization harder. And their failure modes are invisible — the agent makes a bad tool-calling decision, the conversation quality degrades, and you have no structured data telling you why. The ROI Engine takes the opposite position: the configuration defines exactly what each feature needs. The pipeline assembles context deterministically. The LLM receives a complete package and produces output. No tool-calling. No retrieval decisions. No reasoning about what to do next. Context quality over agent autonomy. Determinism over flexibility.
The second category is LLM routers — RouteLLM, Martian, Not Diamond, OpenRouter. These systems solve a real problem: given a query, which model should handle it? RouteLLM trains classifier models on human preference data to route between a strong model and a weak model, achieving cost reductions of up to eighty-five percent while maintaining ninety-five percent of the performance of the expensive model. Martian provides a unified gateway that dynamically routes requests in real time. These are useful systems. But they optimize for query complexity — routing simple questions to cheap models and complex questions to expensive ones. This is single-dimension optimization on a single-turn basis. The router looks at the incoming query, classifies it, routes it, and forgets. It does not learn from outcomes. It does not know whether the conversation converted. It does not optimize for booking rates, or revenue, or customer lifetime value. It optimizes for the proxy metric of response quality on a per-query basis.
The ROI Engine optimizes for the business outcome across the entire conversation lifecycle. Thompson Sampling does not select models based on query complexity. It selects based on which provider-model-prompt combination has historically produced the best conversion outcomes for this product, this feature, and this visitor segment. The feedback signal is not "did the response look good" — it is "did the visitor book a meeting." That is a fundamentally different optimization target, and it produces fundamentally different selections. A model that writes beautiful prose but fails to extract qualification signals will be penalized. A model that produces slightly less polished language but consistently drives bookings will be promoted. The system does not care about benchmark scores. It cares about revenue.
LLM routers optimize per-query: which model for this question? The ROI Engine optimizes per-outcome: which model-prompt-timing combination converts this visitor segment? One reduces cost. The other increases revenue. They are not the same problem.
The Model Explosion Is Coming. The Engine Is Already Preparing.
Here is the landscape that is arriving and that the architecture was built to exploit. In the last twelve months, the number of frontier-capable models has more than doubled. OpenAI, Anthropic, Google, xAI, DeepSeek, Mistral, Groq, Cohere, Meta — each releasing multiple model tiers at different price points, with different capabilities, at different latencies. DeepSeek undercut the market on reasoning capability at a fraction of the cost. Groq achieved inference speeds that made real-time streaming viable for use cases that were previously impractical. Google released Gemini Flash variants that dropped the cost of basic language tasks to fractions of a cent per conversation. Every quarter brings new models that are either cheaper, faster, better at specific tasks, or all three.
For any system that statically assigns a model, this is a maintenance burden. Every time a new model launches, someone has to evaluate it, benchmark it, configure it, deploy it, and monitor it. For the ROI Engine, it is a database entry and an API adapter. You add the new model to the prompt-model-links table. You add its credentials to the model-configs table. Thompson Sampling starts exploring it immediately — running it on a percentage of free-tier conversations, measuring outcomes, updating the Beta parameters. If the new model outperforms the incumbent for a particular product-feature-segment combination, the system converges toward it automatically. If it underperforms, the system deprioritizes it. No manual benchmarking. No A/B test configuration. No deployment cycle. The system is always preparing the next best combination in the background, on live traffic, continuously.
And the optimization is not single-dimensional. Cost is one axis. But the system tracks and can optimize across multiple configurable dimensions simultaneously. Response latency — because a model that takes four seconds to respond loses visitors differently than one that responds in 800 milliseconds. Quality validation pass rate — because a model that produces malformed JSON twenty percent of the time burns fallback budget and increases effective cost. Conversion rate — because the model that produces the highest booking rate at a given price point is not necessarily the cheapest model or the most expensive one. Fallback trigger rate — because a model that requires frequent fallback to secondary providers has hidden operational cost that does not appear in the per-token pricing. Each of these dimensions is tracked per exchange, stored in the routing-decisions table, and available for the optimization loop to weight according to the business's priorities.
Consider what this means operationally. An outage at OpenAI does not produce an outage in your system. The three-tier fallback chain routes to the next provider. Thompson Sampling observes the failure, increments the beta parameter for the affected arm, and begins deprioritizing it in subsequent selections. When the provider recovers, successful conversations increment alpha, and the system rebalances. No human intervention. No incident response. No downtime. The system treats provider instability as a signal, not a crisis. It was designed this way from day one — not because provider outages were a theoretical risk, but because they are a certainty in a world of geopolitical tension, energy grid instability, and the concentration of AI compute in a handful of data center regions.
The price trajectory of frontier models points in one direction: down. Every new entrant undercuts the previous generation. Every efficiency breakthrough at the silicon level reduces inference cost. Every open-weight release compresses the margin that proprietary providers can charge. For a static system, falling prices are a manual savings opportunity — someone notices, reconfigures, deploys. For the ROI Engine, falling prices are automatically exploited. The moment a cheaper model achieves comparable outcomes, Thompson Sampling discovers it through exploration and converges toward it through exploitation. The cost curve bends automatically. The ROI improves automatically. The margin expands automatically. This is not a feature of the system. It is the system.
Never tied to one model. Never tied to one prompt.
Every combination is tested on live traffic. The best is always serving. The next best is always ready.
Model × prompt performance matrix
Scenario simulation — click to see the system adapt
Thompson Sampling selects in real time
35+ arms ranked by conversion outcomes — not benchmarks, not query complexity
Multi-dimensional ROI scoring
Every arm is measured on what matters to the business
All providers healthy
If any provider fails, the next-best tested combination is ready in milliseconds — no manual intervention, no downtime.
The patented continuous learning loop
Each conversation is a learning event. Each outcome adjusts the next selection.
vs. alternatives
LangChain / LangGraph — you build the learning loop
RouteLLM / Martian — routes by query, no outcome learning
Static config — manual model swap each time
Single provider — one outage = your outage
Every new model that launches, every price cut, every provider outage, every shift in capability — the ROI Engine absorbs it automatically. It does not need to be told. It does not need to be reconfigured. It explores, measures, converges. The system was designed for a world where the model landscape changes every quarter. That world is here.
The Patented Flow: How Continuous Learning Actually Works
Recent research from Applied Compute has formalized something that reinforcement learning practitioners have long intuited: not all training samples carry equal information. In their work on sample leverage, they demonstrate that in a binary reward setting — success or failure — when a model succeeds only ten percent of the time, each successful outcome carries eighty-one times more learning signal than a failed one. The rare outcome teaches more than the common one. They built a batch selection algorithm around this principle, discarding low-leverage samples to speed up training by allocating more compute to high-signal data.
The ROI Engine does not need a batch selection algorithm because the patented flow implements leverage-weighted learning continuously, in production, through the mechanics of the Beta distribution itself. This is not an analogy. It is the same mathematical principle expressed as an operational pipeline. The patent documents the exact flow that makes this work, and it is worth walking through step by step because the pattern — not any single component — is the innovation.
Step one: the exploration decision. The Routing Orchestrator reads the tier-based exploration rate from configuration. For a free-tier user, the rate is twenty percent. The system generates a random number. If it falls below the exploration rate, a random provider-model-prompt combination is selected — this is the exploration arm. If it falls above, Thompson Sampling selects the arm with the highest sampled theta from its Beta distribution — the exploitation arm. This is the compute allocation decision: free-tier conversations absorb the exploration cost, paying customers receive optimized selections. The exploration budget is not wasted compute. It is the system's highest-leverage sampling.
Step two: the conversation executes. Context assembly, prompt building, LLM execution, quality validation, outcome tracking — all run identically regardless of whether this is an exploration or exploitation conversation. The visitor does not know. The pipeline does not care. The same fifty states process every conversation. But the metadata is captured: which arm was selected, whether exploration or exploitation, the cost, the latency, the quality validation result.
Step three: the outcome fires asynchronously. After the visitor's conversation completes — whether they book, abandon, subscribe, or close — the chat handler publishes the exchange-complete event to EventBridge. The post-processing Lambda writes the outcome to the routing-decisions table. Then, asynchronously, the Beta parameters for the selected arm are updated. If the conversation produced a booking: alpha increments by one. If the conversation was abandoned: beta increments by one. The update writes to both Redis (for sub-millisecond access on the next conversation) and DynamoDB (for durability). This is the learning step — and it happens after every single conversation, not in batches.
Step four: the next conversation benefits immediately. When the next visitor arrives — potentially seconds later — the Routing Orchestrator reads the updated Beta parameters from Redis and samples from the new distributions. The arm that just produced a booking has a slightly higher alpha. Its sampled theta will, on average, be slightly higher. The arm that just failed has a slightly higher beta. Its theta will trend lower. The system has already learned. No retraining. No batch cycle. No human review. The learning is continuous, incremental, and instant.
Here is where the sample leverage principle manifests naturally. When you add a new model — say a provider releases a new variant next month — you insert a row in the prompt-model-links table and a credential in model-configs. The new arm starts with a prior of Beta(1, 1) — a flat, uninformative distribution. Thompson Sampling will occasionally select it during free-tier exploration. The first conversation on that arm that produces a booking shifts the distribution from Beta(1, 1) to Beta(2, 1). That single outcome moves the expected value from 0.50 to 0.67. Compare that to an established arm at Beta(45, 15) — one more success moves the expected value from 0.75 to 0.754. The new arm's first success carries enormous leverage. The established arm's forty-sixth success barely registers. The Beta distribution does the leverage weighting automatically. No threshold tuning. No sample selection algorithm. The math handles it.
And the flow is symmetric for negative signals. When a provider has an outage, every conversation routed to that arm fails. Beta increments rapidly. Thompson Sampling deprioritizes the arm within minutes, not hours. When the provider recovers, successful conversations increment alpha and the arm rebalances. When a cheaper model begins outperforming an expensive one — because frontier models are improving while prices are falling — the exploration conversations discover it, the Beta parameters shift, and exploitation converges on it. The flow pattern documented in the patent — exploration decision, pipeline execution, async outcome tracking, parameter update, immediate availability — is what makes this possible. It is not a feature bolted onto the pipeline. It is the pipeline.
The distinction from every other approach in the market is worth stating plainly. Batch RL systems collect samples, select the high-leverage ones, retrain, and deploy. That cycle takes hours or days. LLM routers like RouteLLM classify queries by complexity and route statically — they do not learn from outcomes at all. Agentic frameworks like LangGraph give you the graph primitives to build a learning loop, but the learning loop itself is your problem to solve. The ROI Engine's patent documents a complete, closed-loop flow where exploration, execution, outcome measurement, and parameter update are integrated across the Step Function states, the EventBridge event bus, the Redis cache, and the DynamoDB persistence layer. Each component is individually unremarkable. The pattern — the specific sequence of states that turns every conversation into a learning event — is what no prior system has implemented.
The Beta distribution is a natural leverage-weighting mechanism. A new model's first successful conversation carries more learning signal than an established model's hundredth. The patented flow — exploration at the selection state, execution through the pipeline, async tracking via the event bus, parameter update to Redis and DynamoDB — ensures that signal reaches the next conversation in seconds, not hours. Every conversation teaches. Every outcome adjusts. The system never stops learning.
The Entire Codebase Is AI-Generated
There is one additional fact about this system that belongs in the record. Every line of code — every Lambda function, every Step Function state machine definition, every Terraform infrastructure-as-code module, every DynamoDB table schema, every EventBridge rule, every API Gateway configuration — was generated by AI under the architect's direction. Not scaffolded by AI and then hand-edited. Directed and generated. The architect — a single person — designed the system, conceived every mechanism described in this patent, made every architectural decision, chose every pattern, and directed the AI to implement each component. The inventions are human-conceived. The implementation was AI-produced. The patent claims describe the system architecture and methods — the product of human design — not the code that implements them.
This is not an asterisk. It is a proof point. The system described in this patent — fifty states across two nested Step Functions, seven LLM provider integrations, five DynamoDB tables with cross-table optimization loops, dual-database attribution, Bayesian multi-armed bandit optimization, asynchronous event-driven post-processing — was built by one person using AI as the implementation layer. One person. Not a team of twenty. Not a twelve-month development cycle. One architect with AI doing the L1-through-L3 work of writing code, while the architect operated at L4 and L5 — seeing the connections between domains, designing the abstractions, making the decisions that no model could make because no model has the context of building a business, serving customers, and living with the consequences.
If you read our previous post on why the corporation cannot create, this system is the existence proof. The solo founder with AI-powered infrastructure is not a theory. It is a patent filing with ten claims, fifty production states, seven provider integrations, and a USPTO application number. It is not coming. It is here.
Application number 64/013,836. Filed March 23, 2026. Ten claims. Six integrated innovations. Fifty pipeline states. Seven LLM providers. One architect. The tools arrived. Someone used them.
What This Means For Co-Creators
If you are a co-creator on the ROIRoute platform — or considering becoming one — here is what the patent filing means in practical terms. The system that qualifies your leads is not a chatbot. It is a patented orchestration engine that dynamically adapts its conversation strategy based on real-time signal analysis, selects the optimal AI model for your visitor segment using Bayesian optimization, and switches between specialized prompt configurations at exactly the right moment — not when the AI thinks it should, but when the math says it should. Your leads are qualified by a system that is continuously learning which combination of model, prompt, and timing produces the best outcomes for your specific business.
The lead intelligence email you receive before every meeting is not a summary the AI wrote. It is the output of a system that tracked the visitor from ad click through page behavior through every conversation exchange, extracted structured signals at each step, computed a qualification score, and assembled an intelligence briefing that tells you what this person needs, what they told the AI, and what agenda topics to prepare for. Server-side attribution means you know which of your ads brought this person, which parts of your website they engaged with, and how they responded to the AI — even if they are running ad-blockers, even if they cleared their cookies, even if they switched devices.
The infrastructure that powers all of this runs in your own AWS account. Not ours. Yours. The DynamoDB tables, the Lambda functions, the Step Functions, the EventBridge rules — they are deployed in infrastructure you own, on data you control, generating equity in a system that compounds as your business grows. When the patent references multi-tenant isolation through partition keys, it means your data is logically isolated at the database partition level — separated from every other co-creator's data by partition key boundaries in DynamoDB. No shared tables. No commingled records. Your business intelligence is yours.
And the system gets better without you doing anything. Thompson Sampling is running on every conversation. The ML optimization loop is collecting slope data on every exchange. The thresholds that determine when to switch from qualifying to closing are being refined by every conversation outcome across the entire platform. The network effect is not in the data — your data is isolated. The network effect is in the intelligence.
The Filing Is a Timestamp. The System Is the Point.
A patent filing is a legal mechanism. It establishes priority. It documents claims. It creates a defensible position. All of that matters, and we take it seriously. But the filing is not the innovation. The innovation is the system — running, learning, converting, optimizing — serving real businesses, qualifying real leads, producing real intelligence, generating real revenue. Today. Not in a future release. Not pending funding. Now.
The six innovations described above are not independent features. They are an integrated architecture where each component makes the others more effective. Signal saturation detection enables precise switching. Thompson Sampling optimizes the model that executes the switch. Config-driven orchestration enables both to operate across products and tenants without code changes. The attribution bridge closes the measurement loop. The ML optimization loop uses measurement data to improve the switching thresholds. The event-driven post-processing decouples all of this from the visitor's experience. Remove any one component and the system still works. But together, they produce something none of them could produce alone: a conversation system that gets smarter with every interaction, across every dimension, automatically.
The season has changed. The tools have arrived. Someone built with them.
U.S. Provisional Patent Application No. 64/013,836. Filed March 23, 2026. Inventor: Ranjan Gupta. Assignee: JyoLing LLC. The architecture is documented. The system is live. The claims are on record.